
最近では、スマートフォンなどで自分の声で調べものをしたり、自分の声で家電を操作したりする機会も増え、日常生活でも「声で何かをする」ことが身近なものになってきています。AppleのSiriやGoogle Home、AmazonのAlexaなど、みなさん一度は使ってみたことがあるんじゃないでしょうか?
ですが身近になったとはいえ、こういった「音声認識」って、どんな風に実現してて、具体的にどんなことができるのか、実はあまり知らない方も多いのでは??
ということで、今回から「基本から知りたい!音声認識システム」を2回シリーズでざっくり解説します!
「音声認識」とは、人の発した言葉をコンピューターに認識させること。
具体的には「人の話す言葉をテキスト(文字)に変換」したり、「音声の特徴から話し手を特定」することを言います。
今回は、特に私たちにも身近な、話す言葉をテキストに変換する「テキスト化」についてざっくり解説します。
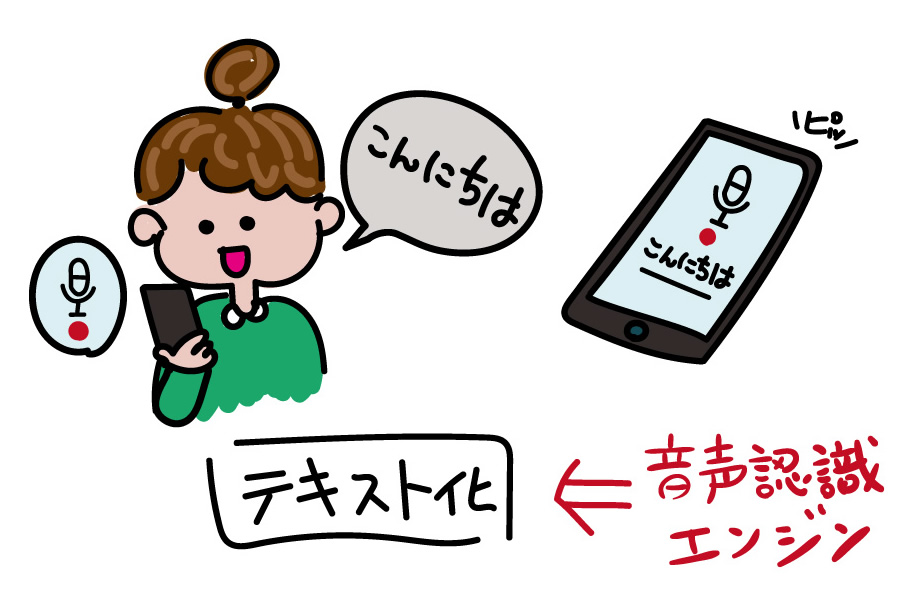
これまで、テキスト化と言えば、指でキーボードを押して入力する作業が主でしたが、音声認識技術を用いたテキスト化は、この入力(インプット)ツールが「キーボード」から「音声(声)」に代わるイメージです。
例えば、議事録を取る際は、話し手が発した言葉を書記が文字にしていますが、音声認識の場合はコンピューターが話し手の言葉を文字に起こします。
音声認識による「テキスト化」はざっくり2つの種類に分けることができます。
それぞれの特徴も併せて見ていきましょう。
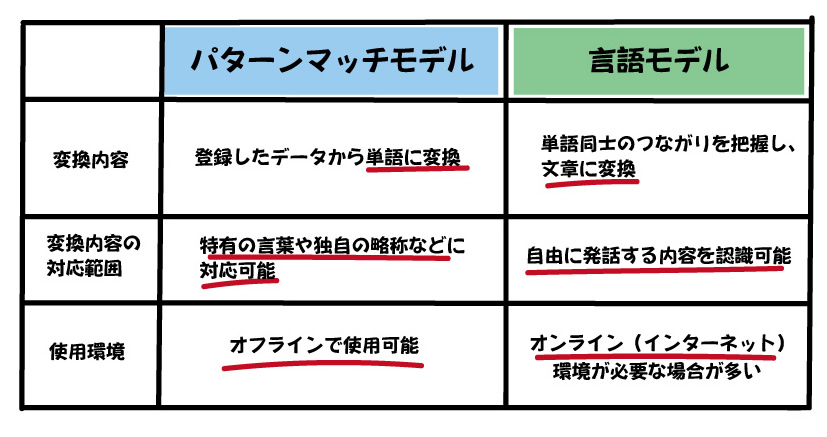
事前に登録したデータと照らし合わせて単語に変換するモデル
・特有の言葉や独自に使用する単語・略称などに対応
・オフラインで使用可能
カーナビに話しかけることで特定の相手に電話をかけられたり、声でエアコンの温度を設定できたりするのには、このモデルが用いられています。
単語同士のつながりをコンピューターが意識し、最も確率の高い組み合わせを求めるモデル
・私たちが自由に発話する内容を認識する
・インターネットに繋がる環境(オンライン)で使用する
Siri や 書き起こしなどが、まさにこのモデルに当てはまります。
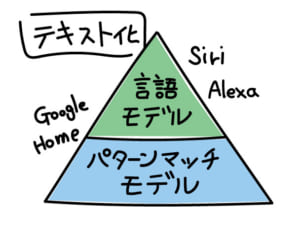
②の言語モデルは、パターンマッチモデルの上位モデルに当たります。
登録された単語同士のつながりをコンピュータが把握し組み合わせることで、自由な発話内容をテキストに変換しています。
パターンマッチモデルより、難易度の高い処理が必要となるためオンライン環境で使用する場合が多いのも特徴です。
①のパターンマッチモデルは、独自に使用する単語や略称に比較的容易に対応でき、パターン化した単語や略称を使用することで、認識の精度を上げることが可能です。
また、インターネットに接続せずとも使用できるため、セキュリティ面での安心感もあり、実は業務上での使用にも適しています。
因みに、当社の“声だけで検査ができる『ゴビボイス』”もこちらの技術を活用しています。
それぞれの特徴を踏まえ、どのような場面で使用したいかによって正しく使い分けることで、音声認識技術を活用するメリットを最大限に享受することができます。
今回は「音声認識システム」の「音声」を認識して「テキスト化」するインプットの部分をご説明しました。
基本的に「音声認識システム」といえば、このインプット部分のこと言いますが、実際にはアウトプット(出力)も音声で行い、音声でのインプット・アウトプットを一連のアプリケーションとする「音声認識システム」が数多く利用されています。
次回は「音声」で出力するアウトプットの部分をご説明します!
⇒ 基本から知りたい!音声認識システム②『音声合成って何?』
お客様の現場に沿った「音声認識システム」を検討してみませんか?
先ずは、ご相談ください!

超文系ながらIT系企業に入社して早〇〇年。入社後は、京都観光のWEBサイト制作に立ち上げから携わり、近年は自社サイトやブログサイトの執筆・運営をメインに奮闘中。
色んな現場や日常で「?」や「これって便利!」と思ったことなど、カンタン解説をモットーに記事を書いています。
保有資格:応用情報技術者
